Welcome to another exciting blog post, where we will dive deep and explore how we helped a long-standing AWS customer regain control over their data lake, consisting of over 3 Petabytes (PB) of S3 data.
This customer embarked on their cloud journey over a decade ago, embracing the scalability and flexibility offered by AWS. Nevertheless, as time went by, they found themselves grappling with a growing challenge – an ever-increasing pool of data that had accumulated within their S3 buckets. Data management practices had adjusted with growth, however, the customer had no clear visibility into which data was essential to retain and which could be safely removed.
How can we decide what needs to be retained if we don't have visibility of the inventory we have?
Building inventory to understand what we already have
To get started, we collaborated closely with the customer's architect team to have a comprehensive understanding of their data scenario. Together we worked out the kind of data stored in their S3 buckets, taking into account the age, size, and access patterns of the stored objects. With that information on hands, we started to plan a strategy to identify data that could be safely removed without impacting ongoing operations and compliance requirements.
To handle the immense scale of data involved, we took advantage power of both AWS's and Hestio's rich suite tools. As starting point, we benefited from some of our own tooling to quickly check what were the top 10 S3 buckets by size:
awsh report-s3-usage
Name Objects Size SizeGB
------------------------------------- ---------- --------- --------
customer-example-dake-lake-01 206203909 752.6TiB 770702.18
customer-example-dake-lake-02 16250214 462.8TiB 473900.37
customer-example-dake-lake-03 141235986 316.1TiB 323710.44
customer-example-dake-lake-04 117097668 242.1TiB 247921.86
customer-example-audit-log 480458594 180.0TiB 184280.81
customer-example-dake-lake-05 27890716 179.7TiB 184037.67
customer-example-dake-lake-06 163981 149.0TiB 152594.06
customer-example-dake-lake-07 102020546 74.1TiB 75894.99
customer-example-dake-lake-08 545534 58.8TiB 60205.55
customer-example-dake-lake-09 27548785 53.8TiB 55085.02
With that information, the next step would be to identify what data is necessary to keep and that is in actively use.
This would be straight forward if the S3 buckets had Amazon S3 Intelligent-Tiering turned on for all their buckets, which would identify objects according their storage classes. However, by using another Hestio tool, we could identify that from top 10 buckets, 3 of top 5 were not covered by intelligent tiering:
awsh report-s3-features
Name Intelligent Tiering Versioning
------------------------------------- ------------------- ----------
customer-example-dake-lake-01 Off Enabled
customer-example-dake-lake-02 Off Enabled
customer-example-dake-lake-03 On Enabled
customer-example-dake-lake-04 On Enabled
customer-example-audit-log Off Disabled
customer-example-dake-lake-05 On Enabled
customer-example-dake-lake-06 On Enabled
customer-example-dake-lake-07 On Suspended
customer-example-dake-lake-08 On Disabled
customer-example-dake-lake-09 On Enabled
In other words, it means those buckets (around 1.3 PB size) were responsible for up to 95% of the costs according to the pricing available from the AWS documentation. Transitioning data from Standard tier to lower tiers is a proven method to bring cost reductions.
Therefore, our first action was to immediately enable intelligent tiering on the missing buckets.
Significant cost reduction can be built into the managed object storage used by AWS customers by simply selecting a default data management policy that will automate the tiering of objects stored based on how often and how frequently the objects are accessed
Right tools, right scale
Without a pattern regarding retention of managed object storage classes, we ended up needing to identify which objects had to be retained by other means. As with many cases like this, combining existing tools with a little scripting is often the approach taken - for example; a Python utility to list all bucket objects and identifying its owner. A traditional approach would be almost impossible due the following circumstances:
- ListObjects API call is able to return up to 1000 objects per API call. We had more than 1 billion of objects to list, which means that this operation would take days to complete, and for sure the session tokens would expire and we would face throttling due to number of API calls made.
- Identifying owners per object level would need a lot of effort and some objects are simply randomly generated by applications and cannot have the owner identified only by its key/size.
Given these challenges, we opted to look for alternatives to get insights on the data:
Amazon S3 Server Access logs: A combination of Server Access Logs, Inventory reports and Athena queries would be the ideal solution. With this solution we would be able to check when an object received GetRequest in a time frame and determine whether the object is in use or not, however, customer
auditbucket which stores the Server Access logs had almost 0.5 billion of objects, which made impossible for Athena to perform queries on so many objects and compare the results with Inventory report.Amazon S3 Storage Lens: That tool provide really good insights by visual graphs about Storage classes usage, up to Top 10 prefixes per bucket and its size, object count and trends for the bucket, However, we felt limited by the capabilities offered as you neither can customize it to offer more granularity in the prefixes levels (For example, bring the top 10 prefixes of the top 5 prefixes) nor get insights of what kind of objects is this bucket storing. And when you find a way to customize it, you will need to wait at least 24h for the next report collection.
Amazon S3 Inventory: Definitely it is a must tool, it will bring information of every single object and its details like size, last modified date, storage class to say a few. It also creates the reports in
Apache Parquet or ORCwhich is already optimized to perform queries using services like Amazon Athena. We confirmed that this tool was the perfect fit to understand the customer data and generate useful reports for their decisions making.Amazon Athena: In a combination with Amazon S3 inventory, it will bring all the capabilities wanted to generated useful and customized reports.
Insights Unveiled
By configuring the buckets to generate S3 Inventory reports via Terraform we were able to automate this operation across all buckets and have the reports of all buckets generated at once.
To perform the Athena queries and finally generated the reports, we also provisioned:
- Athena Database
- Athena Table following AWS best practices per bucket inventory report.
- Created a Python utility to query the Amazon Athena tables. The utility expects some parameters to work properly, they are database, table, bucket to output query logs, full date the S3 inventory report has been generated:
awsh report-s3-inventory \
-d s3_inventory \
-t customerexampledakelake01 \
-o s3://customer-emea-audit/athena/ \
-f 2023-06-18-01-00
The tool is by default generating the following reports and saving them as CSV files on current directory:
- Storage classes and its size
- Top 50 prefixes by size (nested)
- Top 10 file extensions
- Intelligent tiering frequent/infrequent/archiveInstant tiers and their each total size
- ArchiveInstant files
The intention of this tool was to generate an overall insight with a main focus on "ArchiveInstant Files" report. This report brings information about any existing objects that have not been accessed for 90 consecutive days and is automatically moved to the Archive Instant Access tier, the idea was to delete all data not used at least for 90 consecutive days.
We then would tag any of reported objects to be deleted via S3 Batch Operations and delete them using Lifecycle policies. That workflow could be automated to run every x days/weeks/months as designed below:
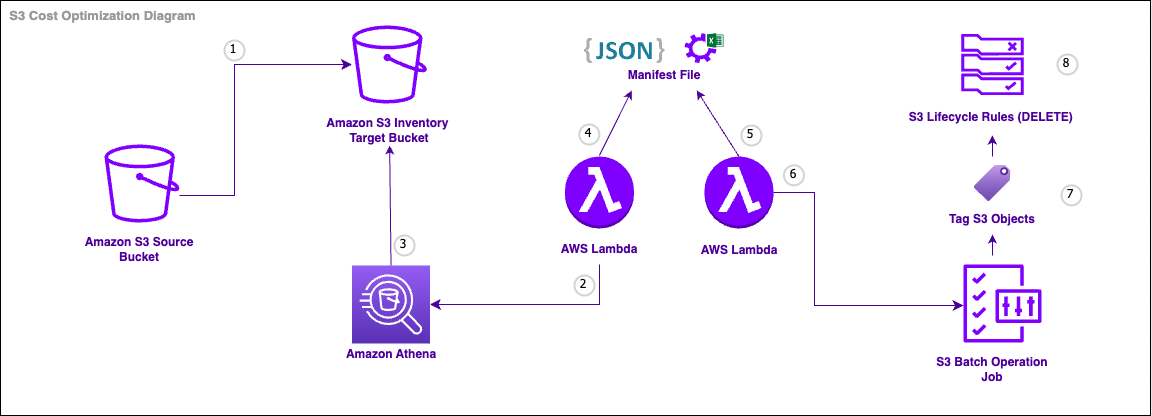
The interesting aspects the above diagram brings are the following:
- S3 Batch Operations: This tool is really needed as Lifecycle policies alone cannot perform delete operations with advanced customization, such as object level, but only prefixes and tags. In order to tag so many objects, only Batch Operations have a session token that lasts enough and will not throttle.
- Lifecycle Policies: In short, it performs the delete API calls for free and under the hood. Imagine performing DeleteObjects (up to 1000 objects per API call) for more than 1 billion objects, that would cost significantly and throttles could happen.
Informed decision making
A generic approach to all S3 buckets was not possible in this case. The customer in question had audit and compliance requirements; we did not want to opt for an approach of deleting data not used for at least 90 days, on the basis that it could also delete data that is vital for the systems and compliance regulations, often data rarely used every 6 months or more.
Through close collaboration with the customer, using the developed Python utility, we generated series of reports which brought information about the top bucket prefixes and the content on them. Some data owners had different type of requests and for each of them we generated customized reports, here are few examples:
- Nested prefixes by size from the top 50 prefixes.
- All objects not modified in the last 1 year, 6 months and 3 months from a specific prefix.
- All objects with a specific extension.
- Top files by size in a specific prefix.
From the reports generated and analysis made, here are some examples we could identify:
customer-example-dake-lake-01: This bucket is used to staging files for testing and later on be utilized in production. The data there should be purged after 1 year, however, more than 7 years of data was being retained.
customer-example-dake-lake-02: This bucket intention is to save SQL backups, the company internal policy to retain the backups varies from 30 to 90 days, however, the data there, was being retained for several years.
customer-example-audit-log: The intention of this bucket is to save all the Server Access Logs from all S3 buckets within the AWS account. The company internal policy recommends to keep the data from a minimal of 3 months, however, from the reports we confirmed the data was being retained for more than 7 years.
We also were able to establish a governance framework that would prevent a similar data accumulation issue in the future by implementing regular audits, establishing data retention policies via Lifecycle Policies, and promoting best practices for data management, the customer was empowered to maintain a lean and efficient data lake moving forward.
Cost reduction by automating AWS governance
The journey of analysing over 3 PB of S3 data with our customer was truly transformative. By leveraging the power of both the AWS and Hestio tools, we helped the customer regain control over their data lake by identifying and removing more than 1 PB of S3 unnecessary data, at a saving of over $250,000 USD per year.
Along the way, we unveiled invaluable insights that provided a foundation for ongoing cost savings and operational improvements.
This use case serves as a testament to both the scale of AWS and highlights the importance of implementing data management practices from the outset. As organizations continue to accumulate vast amounts of data, it is imperative to embrace tools and strategies that empower efficient storage utilization, cost optimization, and the extraction of meaningful insights.
Stay tuned for more Hestio's blog posts, as we continue to explore innovative ways to maximize the potential of cloud technology and unlock the true value of your data assets.
At Hestio, we have taken our experience with designing and building on cloud to codify these patterns and made them available as a low-code pattern library for AWS. Why spend time and effort on reinventing the wheel when it's already a solved problem? Would you start developing office productivity software in a world where Microsoft Office already exists?
If you'd like to find out about worX, our low-code patterns library for AWS you can read more here or get in touch today to schedule a demo.
If you'd like to find out more about the products and services Hestio has to offer, select one of the options below.